

A Better Approach: Robust, Real-World Tests
Modern applications are highly complex, with sophisticated underlying algorithms and data access patterns. The measured efficiency of a processor—its IPC—can vary substantially not only between applications, but also between different workloads in a single application. Many workloads also involve displaying graphics on screen and reading or writing data to and from local or network storage, and the accelerators for these operations can also dramatically impact performance. CPU performance is a poor and incomplete metric; how can we do better?
User Tests
One of the best ways to evaluate PC performance is to conduct individual real-world tests that are:
- focused on everyday computing tasks
- designed to mimic real working environments
- built around real-world file and data needs
These tests will do a significantly better job of predicting individual future user satisfaction with their PC and give decision-makers a more accurate performance picture than any published benchmark.
However, this approach is not without its disadvantages. These tests are time-consuming to design and run and can create challenges for decision-makers who rely on measuring performance in a consistent, reliable, and unbiased manner.
Customized Application Script Testing
Beyond individual user testing, the next-best approach is for inhouse developers to aggregate suggested workloads from a variety of different classes of users to create customized application scripts that can deliver application performance metrics that map to real user priorities. While this can improve the consistency of measurements and provide repeatable results, it requires substantial and careful upfront investment and doesn’t always scale well from one PC generation to the next.
Composite Benchmarks
Given the complexity of customized test design, many companies rely on industry-standard PC benchmarks to evaluate system performance. Rather than using a single metric, however, companies should aim to build a broader, more comprehensive picture of performance by building a composite score across several benchmarks.
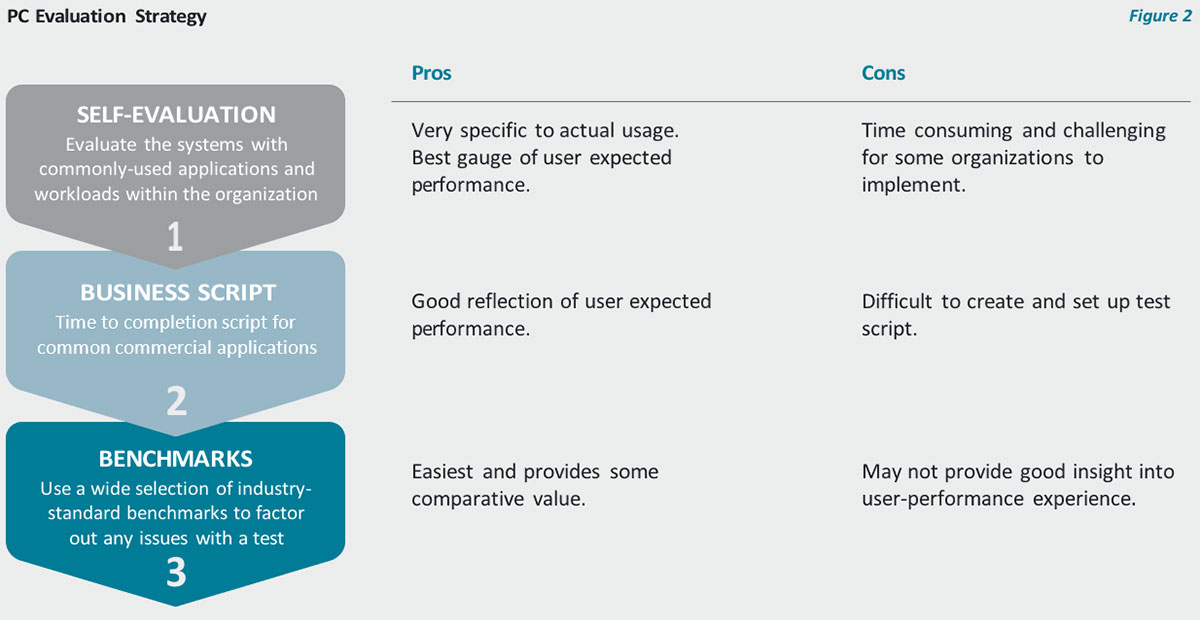
Benefits And Disadvantages
Figure 2 compares three different approaches to evaluating PC performance—benchmarks, application scripts, and user evaluations—and shows how the results have different levels of business relevance.
What Makes A Good Benchmark?
There are commonly two types of benchmarks used to evaluate PC performance: “synthetic” and “application-based.” Both can be useful in the decision process, although individual benchmarks can often have undesirable attributes. Following a general principle of using multiple benchmarks together can mitigate these issues, providing a more dependable picture of performance.
A good benchmark should be as transparent as possible, with a clear description of both what is being tested and how testing is accomplished. In the case of application-based benchmarks, this allows buyers to understand whether workloads being used match their own organization’s usage. Without this transparency, it’s reasonable to worry that benchmarks are being crafted in favor of a specific manufacturer or processor.
Not All Application-Based Benchmarks Are Equal
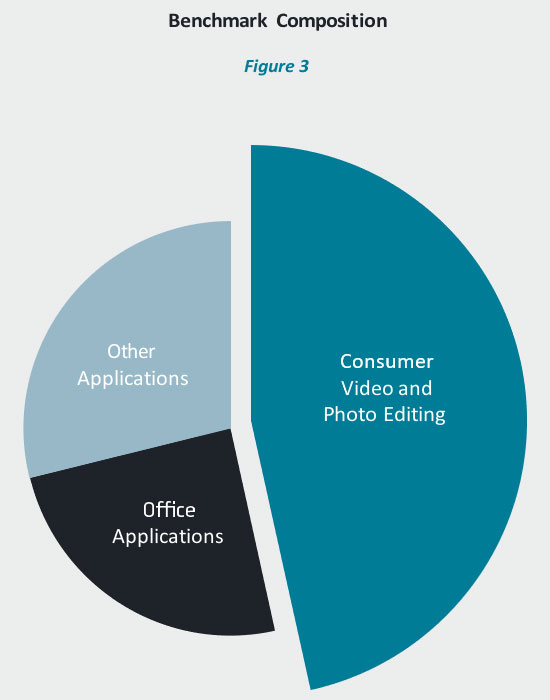
The tests in application-based benchmarks should represent the workloads that are most relevant to the organization. For example, if 30-50% of a benchmark comes from applications that are seldom used in a commercial setting, then that score is probably not relevant.
Consider the benchmark in Figure 3, which is based primarily on consumer-type workloads that are rarely present in an office environment. Therefore, this benchmark would likely not be useful to most commercial organizations.
Some application-based benchmarks measure the off-the-shelf performance and may not represent either the actual deployed version of the application or recent performance optimizations or updates. This is where synthetic benchmarks become very useful.
What About Synthetics?
While application benchmarks show how well a platform is optimized for specific versions of certain applications, they are not always a good predictor of what new application performance will look like. Unlike application-based benchmarks, synthetic benchmarks measure the overall performance potential of a specific platform.
For example, many video conferencing solutions use multiple CPU cores to perform functions such as virtual backgrounds. Synthetic benchmarks that measure the multi-threaded capability of a platform can help predict how well a platform can deliver this new functionality.
A Cautionary Note
It is important to avoid using a narrow measure of performance to drive synthetic benchmarks. Individual processors, even in the same family, can vary in how they handle even a small piece of code.
Synthetic Benchmark Sub-scores
With synthetic benchmarks built on narrow measurement sub-scores, it is important to not overly weight these results. Decision-makers should instead evaluate the composite score, which exercises a broader set of processor functions.
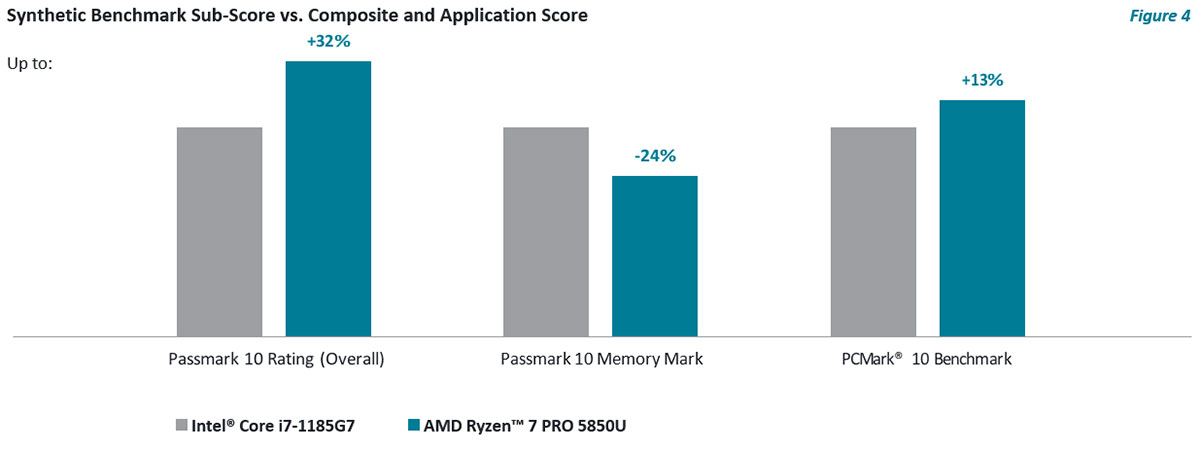
One example is memory sub-scores. These can measure latency and throughput but may not factor in other elements such as a processor cache design that reduces the impact of memory latency on overall application performance.
Figure 4 shows two example processors for which the results for the memory sub-score do not reflect the results from the synthetic benchmark’s composite score nor a system level benchmark score.
A synthetic benchmark score should capture several individual tests, executing more lines of code and exercising different workloads, and then provide an overall composite score. This enables a much broader view of the platform’s performance.
As we can see in Figure 4, synthetic sub-scores can deviate significantly from the composite score or even other system level benchmarks. Sub-scores which exercise less of the capabilities and provide a more limited view can still be utilized, just with less emphasis vs. the composite score.
Measuring For A Multitasking World
Application benchmarks have a hard time simulating the desktop workload of a modern, multitasking office worker, because applications rarely run alone, but multiple applications at once add a larger margin of test error.
Synthetic benchmarks that measure the raw multi-threaded processing power of a platform are a good proxy for the demands of today’s multi-tasking users.
Combine both for clarity
A best practice is to consider both application-based and synthetic benchmark scores together. By combining scores using a geometric mean, you can account for the different score scales of different benchmarks. This provides the biggest, clearest picture of performance for a specific platform, considering both today’s application requirements and ensuring capacity for what comes tomorrow.