

Other Important Considerations
Benchmarks are an important part of a system evaluation, but shouldn’t obscure other considerations.
- Measured benchmark performance can vary by operating system (OS) and application version. Ensure that these versions match what’s in use inside your environment.
- Other conditions can impact scores, such as background tasks, room temperature, and OS features such as virtualization-based security (VBS) enablement. Tests must reflect these details.
- Some users may use relatively niche applications and functions not covered by the benchmarks. Consider augmenting benchmark scores with user measurements and correlating them with synthetic benchmark scores.
Managing Measurement Error
Any measurement will have a margin of “measurement error,” that is, how much it varies from one test to another. Most benchmarks have an overall measurement error in the 3-5% range.
This is driven by a variety of factors, including the limitations of measuring time, the “butterfly effect” of minor changes in OS background tasks, and other nuances.
Did You Know? When a new version of a benchmark is introduced, t often has little or no correlation to the previous version. New workloads, applications, and measurement calculations are included, creating a completely different score. These calculations may also measure only limited workflows. It’s critical to understand these new core components to ensure they still reflect relevant, real-world usage.
One way to overcome this error would be to measure results five times, discard the highest and lowest scores, and take the mean of the remaining three scores.
Building it into the purchasing process
It is important to consider measurement error when setting requirements in purchase requisitions.
If a score of X correlates well with user satisfaction, then the requisition should stipulate that score should be within [X-Epsilon, Epsilon] where epsilon is the known measurement error. When epsilon is not known, it is reasonable to assume it is in the 3-5% range of the target score.
Putting Time Measurement In Context
Some benchmarks compute a score by measuring tasks that are only milliseconds or even less in length, where humans typically deal with timeframes in the seconds and up range. These benchmarks then apply a mathematical weighting formula to the very short task and derive a computed numerical score that may imply a result far outside of what a typical person would perceive.
For example, if a task takes 5ms on one processor and 6ms on another, the benchmark will report that the first is 20% faster, even without any weighting factor applied. However, a real user is not very likely to notice this difference in actual time required to process the function.
Of course, the responsiveness of a computer is always important, but the key is to understand the duration and number of times the function in the test is being measured, any mathematical weighting factor, and how much that would be perceivable to the user.
These measurements can be augmented with tests that are longer in duration, or Time to Completion (TTC) type tests, both of which measure on timescales that are more perceivable and meaningful to users.
Considering Inconsistent Application Performance
Application performance is not a constant and, as such, is always changing. Software venders bring out new versions, change compilers, optimize key functions, or the OS itself changes. As a result, the system performance can change in unexpected ways.
A good example is Microsoft Excel, a common application test used to evaluate PC performance. Microsoft is constantly working to improve performance of Excel, rolling out changes with each update. Their blog on recent changes rolled out in September of 2020 details a wide range of improvements that can significantly impact performance, sometimes even by orders of magnitude.
It’s a great illustration of how “the same” applications performance tests may vary considerably based on which version of the application is being used. And for benchmarks that embed elements of an application, the difference can be even greater. The benchmark may be several years old, using old application code that has little correlation to current performance.
Even with benchmarks that use the installed version of an application, there can be dramatic differences unless the same application versions are used across all tested systems.
Excel performance improvements now take seconds running Aggregation functions – Microsoft Tech Community
Building A More Thorough Benchmark Evaluation
The AMD Ryzen™ 7 PRO 5850U and the Intel Core i7-1185G7 are two processors that are used in a variety of enterprise class commercial systems, and many companies purchasing laptops would consider them as primary processor candidates. When conducting the testing, the battery should be fully charged, since this process can contribute significant thermal load that impacts performance.
For this evaluation to be thorough, a wide variety of different types of tests, including industry common synthetic benchmarks, application benchmarks, and actual application time to complete tests were used. These include:
- CineBench R23 (including 1T and nT)
- Geekbench v5 (including single core and multi-core)
- PCMark® 10 Overall
- PCMark® 10 Express
- PCMark® 10 Extended
- PCMark® 10 Productivity
- PCMark® 10 Digital Content Creation
- PCMark 10 Applications (including Overall, PowerPoint, Word, Excel, and Edge)
- PCMark® 10 Gimp Cold App Startup
- PCMark® 10 Gimp Warm App Startup
- PCMark® 10 APP start
- Passmark 10 Overall (including sub-scores for CPU Mark)
- Passmark 9 CPU Mark (which is very often used in commercial tenders)
- Sysmark 2018 Rating Overall (older but still referenced for some tenders)
- Sysmark 25 Rating Overall
- Puget Photoshop Overall Score
- Puget Photoshop General Score
- Blender Bench CPU-BMW27 (TTC)-sec
- Blender Bench CPU-ClassRoom (TTC)-sec
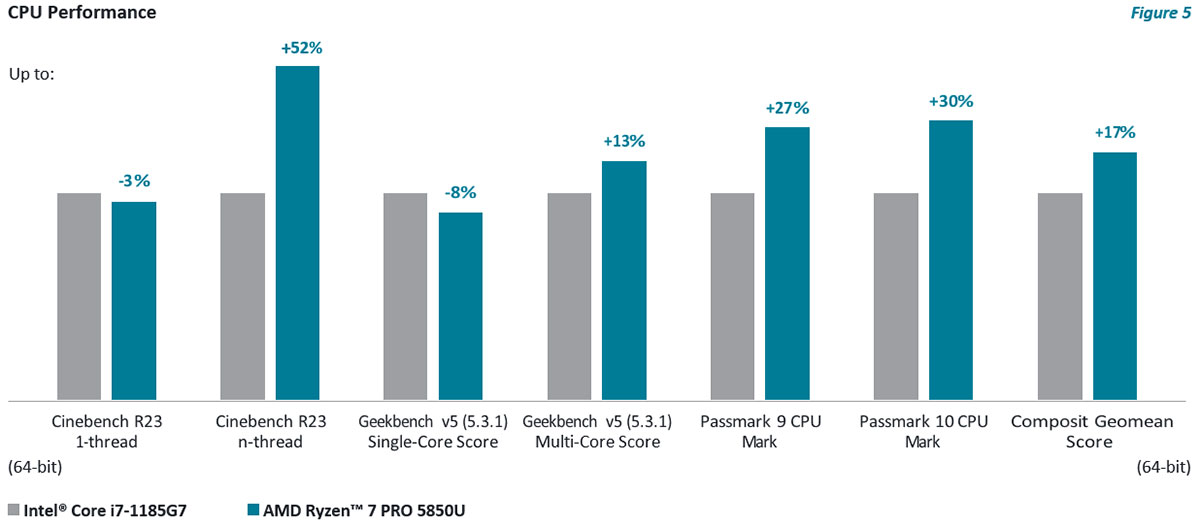
This set of benchmarks is collected from a variety of industry sources and tests different attributes to provide a more comprehensive view of processor and system performance. Assuming a benchmark error can be roughly 3-5%, the following comparisons will consider +/-5% to be roughly equal in performance. Above this, and users will begin to notice a difference.
In addition, a geomean score, the average of the benchmarks used in the analysis, is also provided. This provides an average benchmark score that factors in differences in magnitude between the different benchmarks.
More importantly, averaging multiple different benchmarks from different sources helps address any possible bias or limitation of a particular test by averaging it across many tests.