

Artificial intelligence (AI) are the buzzwords of 2023. Rightly so, as the technology, in its many forms, revolutionises the way in which billions of people go about their lives. From leisure to business and everything in between, there is no facet AI won’t touch. The great challenge for technology companies is to embody meaningful AI at every scale. From datacentres full of racks for heavy-duty training through to client devices running productivity-enhancing workloads locally, Intel views itself as a pioneer in bringing AI everywhere. Let’s examine why.
The AI revolution
AI is an extremely broad church. In its simplest form, it’s a computer’s ability to mimic common human behaviours such as problem solving, understanding commands, learning, and reasoning. Sounds far-fetched, doesn’t it, but your Amazon Alexa or Apple Siri are basic forms of AI. On the other end of the scale, more powerful solutions generate complex, multi-layer answers for limitless questions. I’m sure we’ve all had fun trying ChatGPT or Google Bard large-language models (LLMs).
The smarts behind AI verge on science fiction. Born out of machine learning that has been around for 50 years, deep learning is the bedrock that underpins most AI as we know it. This offshoot uses neural networks to process masses of data – in the same way human brains make sense of the world by accumulating information that ultimately leads to perception – and through an iterative process of learning, determinism, and pattern recognition on potentially billions of inputs, a good model effectively understands the data to draw out useful and accurate insights.
A well-tuned computer vision AI model effectively knows whether a random picture has a cat or dog in it because it understands, through thousands or millions of similar images fed to it during the training phase, which characteristics fit with each animal – four legs and a tail are common to both, for example. It’s this ingrained notion of commonality and associativity that builds meaningful results.
In the same vein, a warehouse pallet, bicycle, or tumour, though absolutely different to each other, have particular characteristics that aid AI in classification and identification.
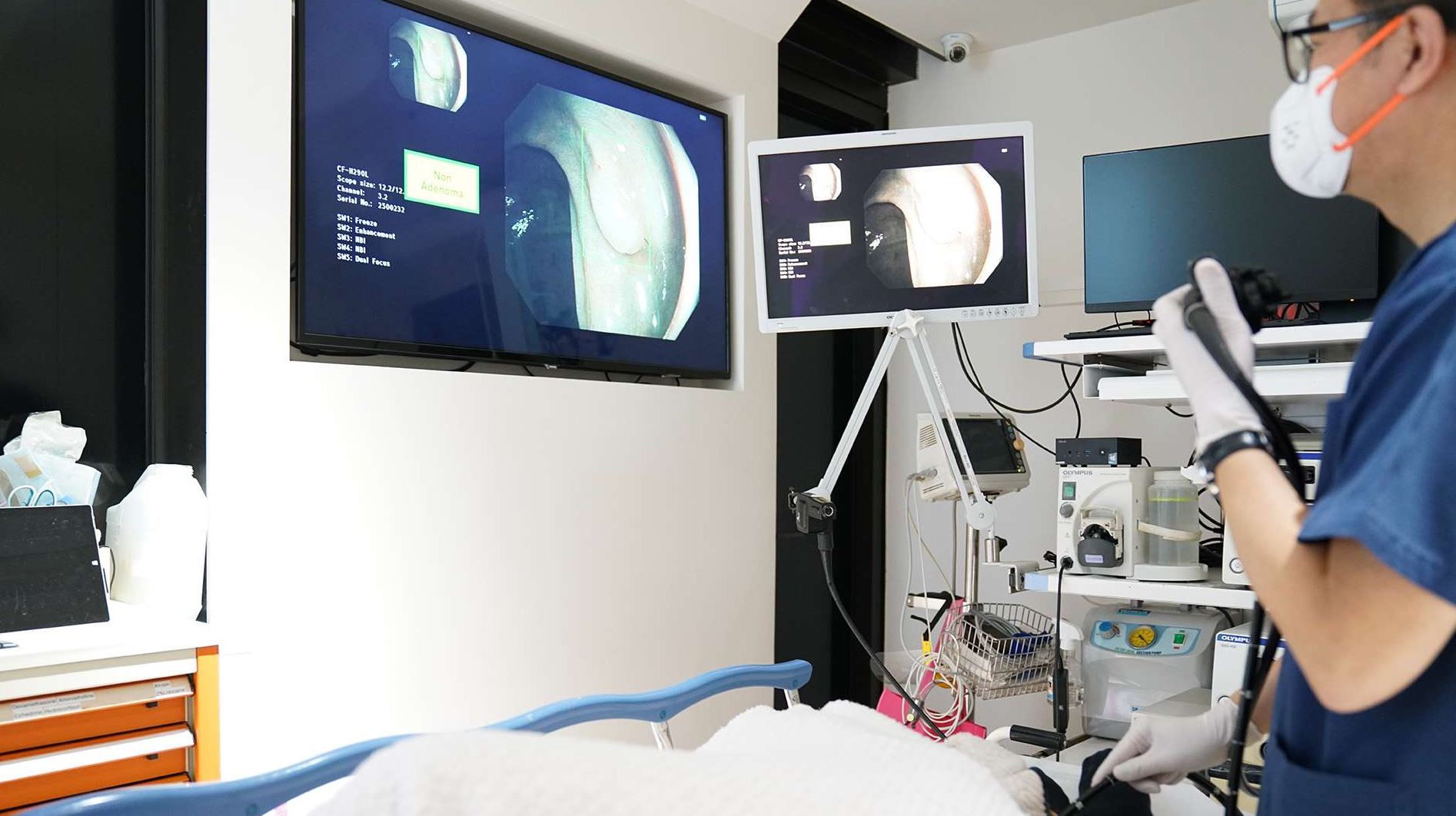
Certain AI excels at this type of pattern recognition that has immediate benefits in, say, the medical world. Powerful models are now better than humans at detecting potential diseases when extrapolating detail from scans. Imagine the relief of AI catching an adenoma that a tired doctor, through no fault of their own, fails to spot after a marathon 12-hour stint. In effect, good artificial intelligence takes out much of the human error caused by extraneous factors. Well-trained algorithms don’t tire. That’s not to say it’s a perfect science, of course – any model is only as good as the quality and quantity of data fed into it – but it’s hard to argue that AI is great tool to use alongside expert human knowledge.
Besides, AI extends to far more than mere computer vision. The same underlying pattern recognition, training and inference mechanism is useful for building new content from seemingly scratch. Ever sat in wonder as generative AI models like ChatGPT reel off paragraphs of useful, context-aware information in seconds, or when Stable Diffusion creates photorealistic imagery from basic text inputs? Mind blown.

A case in point. Here’s me requesting Stable Diffusion XL create a picture with the text prompts of ‘angry man riding a bicycle.’ It’s got a Monty Python-esque vibe, don’t you think?
From the big to the small
The more one does something, the better they become at it. The so-called 10,000-hour rule dictates that practising any skill for this length of time leads to the exponent becoming an expert in it. The same is true of AI, as ever larger and complex models provide more accurate and useful results. Though fun to play with, the latest version of ChatGPT uses, wait for it, a 175-billion-parameter model to generate human-like responses.
“Intel views itself as a pioneer in bringing AI everywhere.”
The truly massive computational ability required to process and draw meaningful insights from billions of data points remains the sole preserve of the cloud. Leading-edge AI necessarily requires wondrous scale. This makes sense, too, as remote datacentres chock-full of specialised hardware churn through heaps of information and, in many cases, return near-instantaneous results. The sheer horsepower required is simply too much for local processing on your desktop PC, laptop, or even an in-house server room. This state of affairs remains largely true for comprehensive training and inferencing today.

Yet we’re entering the blossoming age of AI everywhere. It’s becoming more personal. Whilst technologies such as ChatGPT are marvels in themselves, creating ubiquity through Internet accessibility almost anywhere in the world, businesses and individuals have quickly realised that small-scale AI is just as useful, easy to use, and arguably more secure.
We’re only starting to scratch the surface of how AI will revolutionise the business space, and mark my words, it will happen on every spectrum of the scale. For the office worker, wouldn’t it be great to have on-the-fly language translations, cogent meeting summaries, and human-beating data analysis run on your own laptop… without the wait commonly instigated by online options?
“Yet we’re entering the blossoming age of AI everywhere. It’s becoming more personal.”
Businesses, too, can benefit by using local AI processing for actions that are more mundane but just as important. Computer vision enables physical site management, intrusion detection. General worker efficiency increases by using AI in their regular workflows. There are myriad other use-cases where AI removes some of the burden imposed by the traditional labour-intensive approach.
Empirical evidence is best. As a small business owner, I’m certainly not a fan of sifting through hundreds of emails to find the correct thread pertaining to an obscure request; I’d rather smart neural processing do it and allow me to focus on more important matters. Local AI also has financial benefits as it mitigates against the inevitably higher costs associated with using solely a cloud-served approach.
Getting AI into every nook and cranny is no trivial task, however. True democratisation requires processing at the cloud, client and edge, across heterogeneous architectures and software stacks. Understanding the once-in-a-lifetime business opportunity that runs into a total addressable market (TAM) counted in the tens of billions of dollars, Intel has been busy building the infrastructures required for pervasive AI, across all industries and business segments.
Intel’s plan for AI at scale
Demand for AI remains insatiable when seen through the lens of worldwide opportunity. With billions of non-smart devices in the field, which serve merely as endpoints for cloud-delivered processing, large-scale AI training and inferencing is here to stay. Though models do run on older server hardware typically used for established tasks such as database management, transactional services, and web serving, a step-change in performance requires a whole architecture rethink.
The latest Intel Xeon CPUs have AI firmly in mind. For example, the 4th Generation Xeon Scalable Series devotes precious die space to a technology known as Advanced Matrix Extensions (AMX). Used to process simpler AI, math-intensive AMX is compatible with commonly used data formats – BFloat16 and int8 – and subsequently helps run specific emerging workloads up to 10x faster than prior generations. That’s the step-change I’m talking about.
Today’s presence of AI-infused server hardware is no happenstance; it’s deliberate by design, because CPU architecture finalises many years before production. Helping high-performance computing (HPC) and AI workloads, a new range of Xeon Max Series processors carry up to 64GB of HBM2e RAM. The extra memory helps in loading larger datasets – if you understand AI, you understand workloads are huge – closer to the computational engines and therefore speeds up processing.
Shifting gears into the world of massive AI processing, Intel’s Data Center GPU Max Series and Gaudi2 AI accelerators’ purpose is to facilitate at-scale performance. Oftentimes, multiple server clusters comprising Xeon and Gaudi2 train LLMs. As a pertinent example, most recently, 384 Gaudi2 accelerators took 311 minutes to train a 1% slice of the 175-billion-parameter ChatGPT-3 model widely in use today. I expect a leap in Gaudi2 performance when there’s available software support for the faster-to-train FP8 format.
Scale is truly best exemplified by companies and governments doubling down on AI investment. Leading Intel technologies come together to form Dawn, which is the UK’s fastest AI supercomputer. A cornerstone for the recently announced U.K. AI Research Resource (AIRR) initiative, first-phase Dawn is home to 256 Dell PowerEdge XE9640 servers each carrying two 4th Gen Xeon Scalable processors and four Data Center GPU Max Series GPUs.

Coming online in 2024, Phase 2 promises a tenfold increase in performance. Enough, one would think, to vault up the global TOP500 supercomputer list. This extreme scale, and a harbinger of things to come.
Why personal AI matters
AI everywhere, meanwhile, requires multi-generational investment in purpose-built hardware for personal devices such as laptops or PCs. Going hand in hand, the software ecosystem also needs to build smaller models that run efficiently on the computers themselves. Recent developments in the software space show that text-to-image models (Stable Diffusion), large-language models (Meta’s smallest Llama 2 and DoctorGPT), and automatic speech recognition programs (Whisper) all comfortably fit in below the 10-billion-parameter threshold considered key for local processing… with the correct collection of hardware and software, of course.
Smarter training enables these smaller models to replicate much of the accuracy and usefulness associated with datacentre-type scale. Interesting generative AI and advanced real-time language translation are now far enough along to provide a satisfying experience when using the processor brains contained within a latest-generation ultra-thin laptop.
Nevertheless, there are caveats. Though simpler in nature than cloud-based models, efficient AI processing remains difficult on older CPUs and GPUs – it’s akin to fitting a round peg into a square hole. As in the cloud space, forward-looking processors must have AI in their very DNA.
Addressing the urgent need and released today, Intel Core Ultra chips, previously known as Meteor Lake, use the latest CPU and GPU technology alongside a brand-new neural processing unit (NPU) for running specific AI operations. A good example of this three-processor collaborative approach is in using the offline Meta Llama 2 7bn model. The low-power NPU helps in general LLM processing but takes over sole duties for automatic speech recognition via aforementioned Whisper.
Sure, you can try and run Llama 2 LLM (7bn) on older technology but doing so exposes the way in which even modest local AI computation trips up non-optimised designs. Put simply, a good AI experience requires the right blend of hardware.
“For AI to be everywhere it needs to run on everything.”
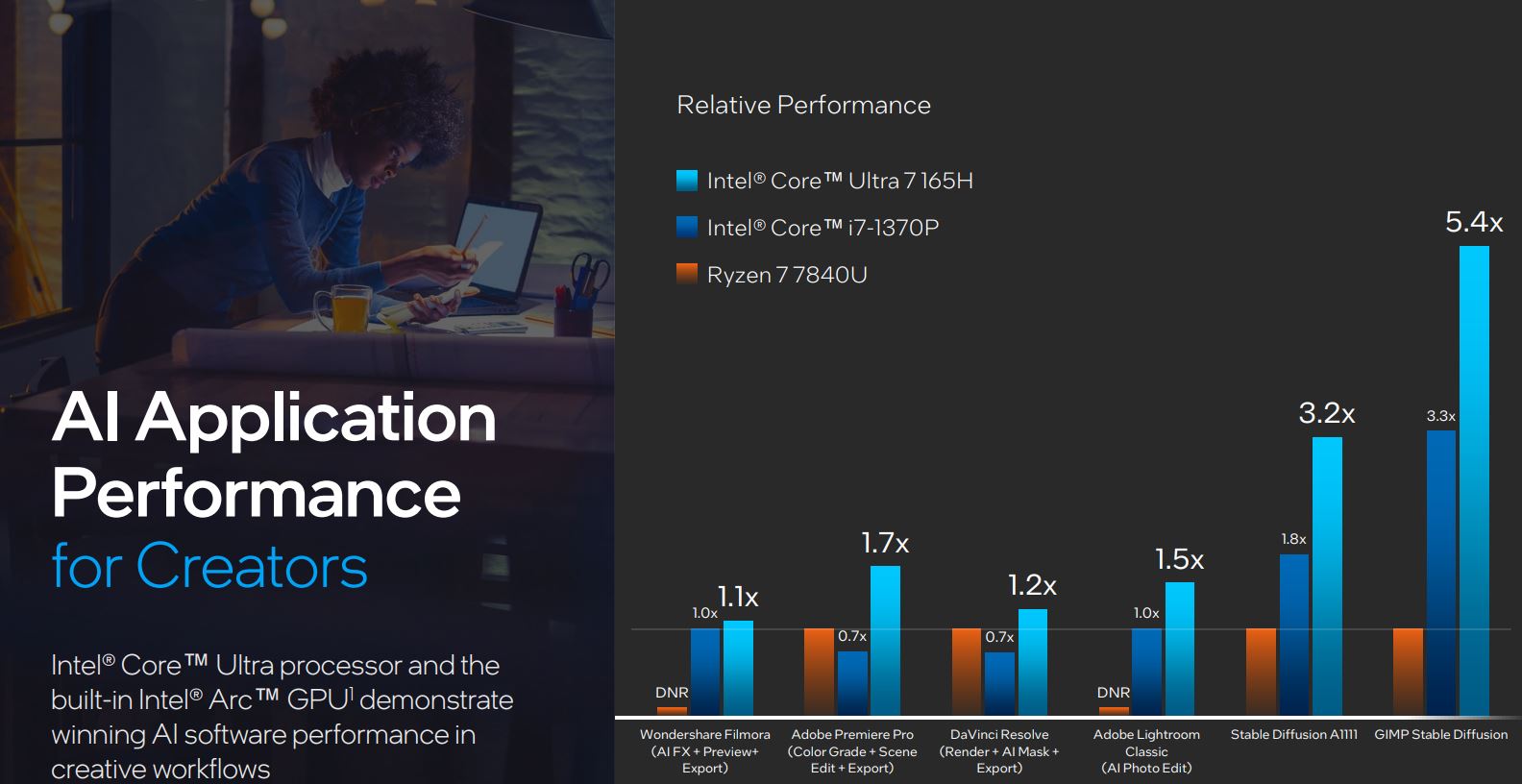
The inclusion of another dedicated processor is a real boon for AI performance for common creative workflows. Take locally run Stable Diffusion as a prime example. The latest Core Ultra 7 165H is almost twice as fast as a last-generation Core i7-1370P and, according to Intel’s numbers, in a different league to rival AMD’s mobile solutions.
And that’s the crux of it. Important emerging workloads have always dictated architecture design. Now, though, there’s enough inertia within all-encompassing AI to demand most future processors carry dedicated hardware. If I was a betting man, subsequent Core processors will devote more silicon for artificial intelligence processing than, say, for traditional execution cores. In effect, the CPU is fast becoming a fully-fledged SoC, and the latest multi-tile Core Ultra is testament to this fact.
“The inclusion of another dedicated processor is a real boon for AI performance.”
As AI is here to stay, real-world implications are profound. It makes little sense, I believe, to purchase client-side processors lacking baked-in AI-specific technologies. Most readers understand CPU and GPU initialisms: NPUs will soon fall into this familiarity bracket, as well.
Simplifying AI development
There’s no turning back on the AI crusade. Speaking to scale, internal research suggests over 100 million Intel-based PCs with some form of AI acceleration arriving in market by 2025. That’s a large install base ripe for development. Appreciating that good software helps drive hardware adoption, Intel is planning on having over 100 AI software partners through 2024. If you build it, they will come.
Much of the research and modelling began in the scientific community and developed on deep-learning frameworks like PyTorch, Caffe, ONNYX, and TensorFlow. Ensuring they work well with heterogenous Intel hardware through a write-once, deploy-anywhere approach, the OpenVINO toolkit simplifies model import and optimisation.
This ease of use is absolutely key in propagating AI through eclectic hardware. Customers need a straightforward route to implement AI for both training and inferencing.
A good example of this approach is the Intel Geti program. The software enables the building of computer vision models for AI applications. Simplicity is key. Geti requires as few as 10-20 images to start iterating and training on. Good for object detection, classification and segmentation, the OpenVINO-optimised software enables rapid prototyping and shortens the time taken to have meaningful AI up and running.
Building smarter solutions
The emergence of AI fundamentally changes how technology companies build forthcoming products and services. Any product roadmap bereft of thoughtful integration is at serious jeopardy of being rendered obsolete immediately.
Most of the current focus resides with huge cloud-accessed datacentres churning out training and inference at incredible scale. This will continue as pent-up demand for existing computation is considerable, augmented by emerging interest pouring in from industries getting to grips with the intrinsic benefits afforded by AI.
True proliferation, however, requires more than compute-intensive datacentres that feed results over the Internet. The next inevitable phase is one where AI seeps into everyday life albeit largely oblivious to the user, and for that to happen it needs to become more personal and run on local devices. It’s not all about the cloud.
This transitional PC revolution is already well underway. For AI to be everywhere it needs to process on everything – be it a laptop, PC or server. Teasing out efficiency demands AI workloads operate on the right silicon, and here’s where the all-new NPU joins the traditional CPU and GPU as brothers in arms.
Bringing these technologies together, Intel’s latest processors leverage this multi-pronged approach by making locally-run AI accessible and efficient. If you’re planning to buy a laptop good for today and better for tomorrow, it certainly pays to invest in a forward-looking design.