

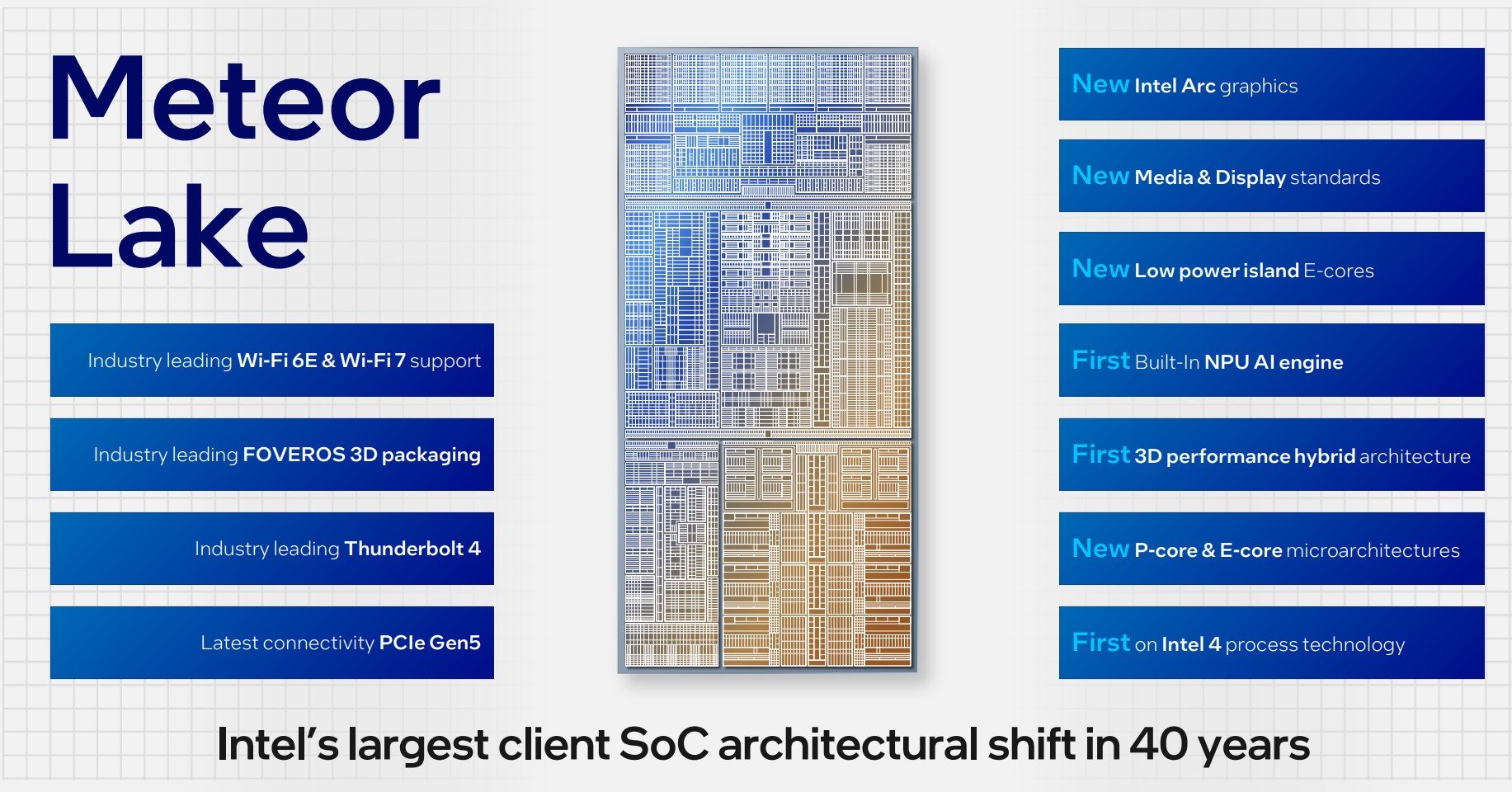
Officially announced today at the Innovation Conference in San Jose, Intel has finally taken the wraps off next-generation mobile client architecture known by the codename Meteor Lake. Described as the largest architectural shift in 40 years by Tim Wilson, VP of the Design Engineering Group, it is the first to use a disaggregated approach composed of four tiles tied together by in-house Foveros 3D advanced packaging technology.
Coming to laptops first and to be productised as 14th Gen Core along with new branding, there’s plenty to be excited about because Meteor Lake lays foundation for how Intel will build out subsequent architectures for many years to come.

Four Tiles Working Together
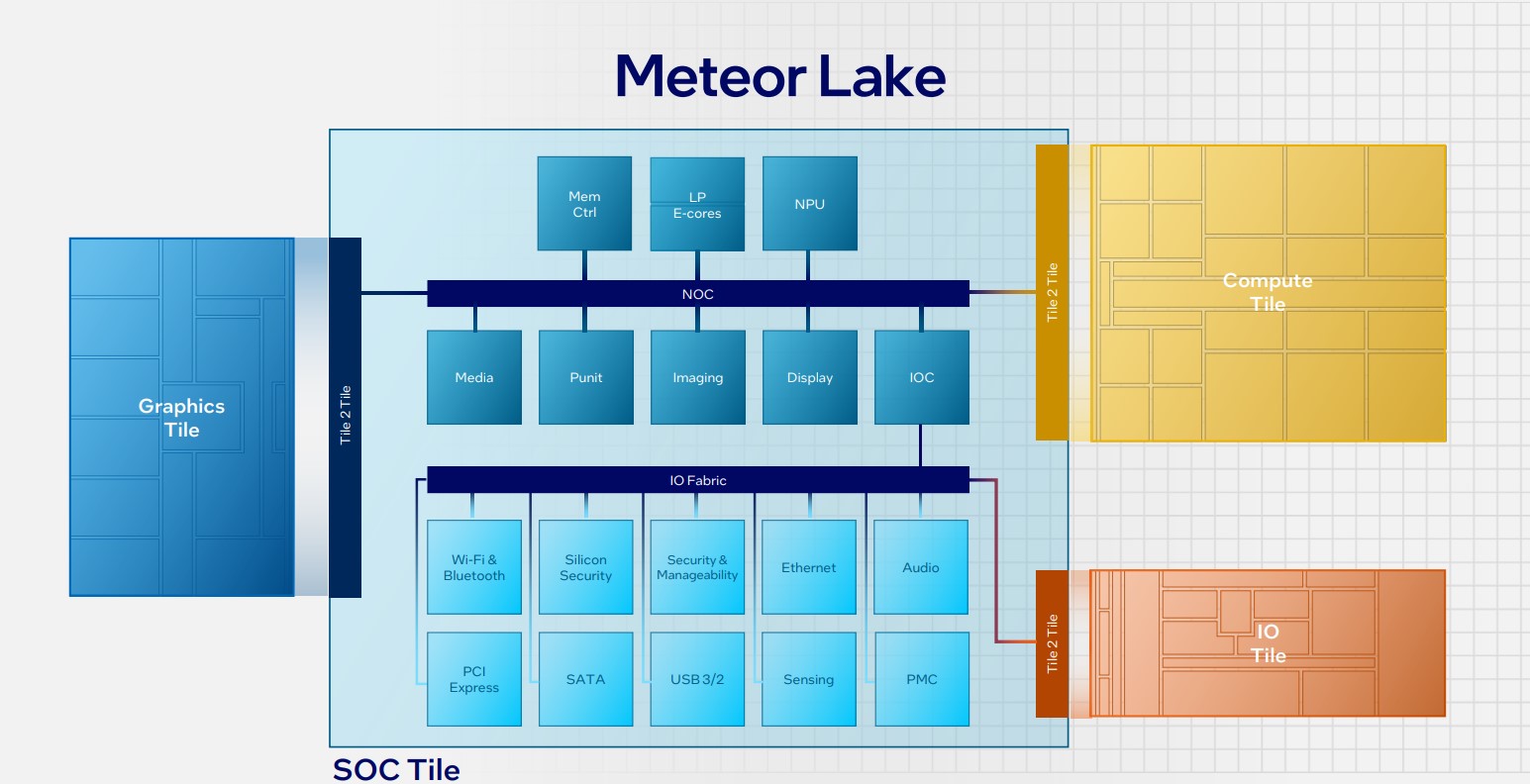
Arguably the most important portion of the design is the Compute Tile, built on a leading-edge EUV Intel 4 process, and home to varying quantities of P-cores (Redwood Cove) and E-cores (Crestmont) that have been microarchitecturally enhanced over today’s Raptor Lake generation. Intel can shoehorn in any combination of cores it sees fit for the particular chip, so you might see, for example, 6 P-cores and 2 E-cores along with their associated caches.
Second is the SOC Tile and it carries over most of the features currently found in the ‘Uncore’ part of any modern Intel chip. A keen departure from tradition, this SOC Tile also features its own E-cores that, according to Tim Wilson, are “ideal for an entire class of workloads common in today’s PCs.” Combined with the regular cores in the Compute Tile, Intel refers to the trio – P-core, E-core, SOC E-core – as a 3D Performance Hybrid Architecture, and it’s the difficult job of also-next-generation Thread Director to arbitrate the correct workload amongst them.
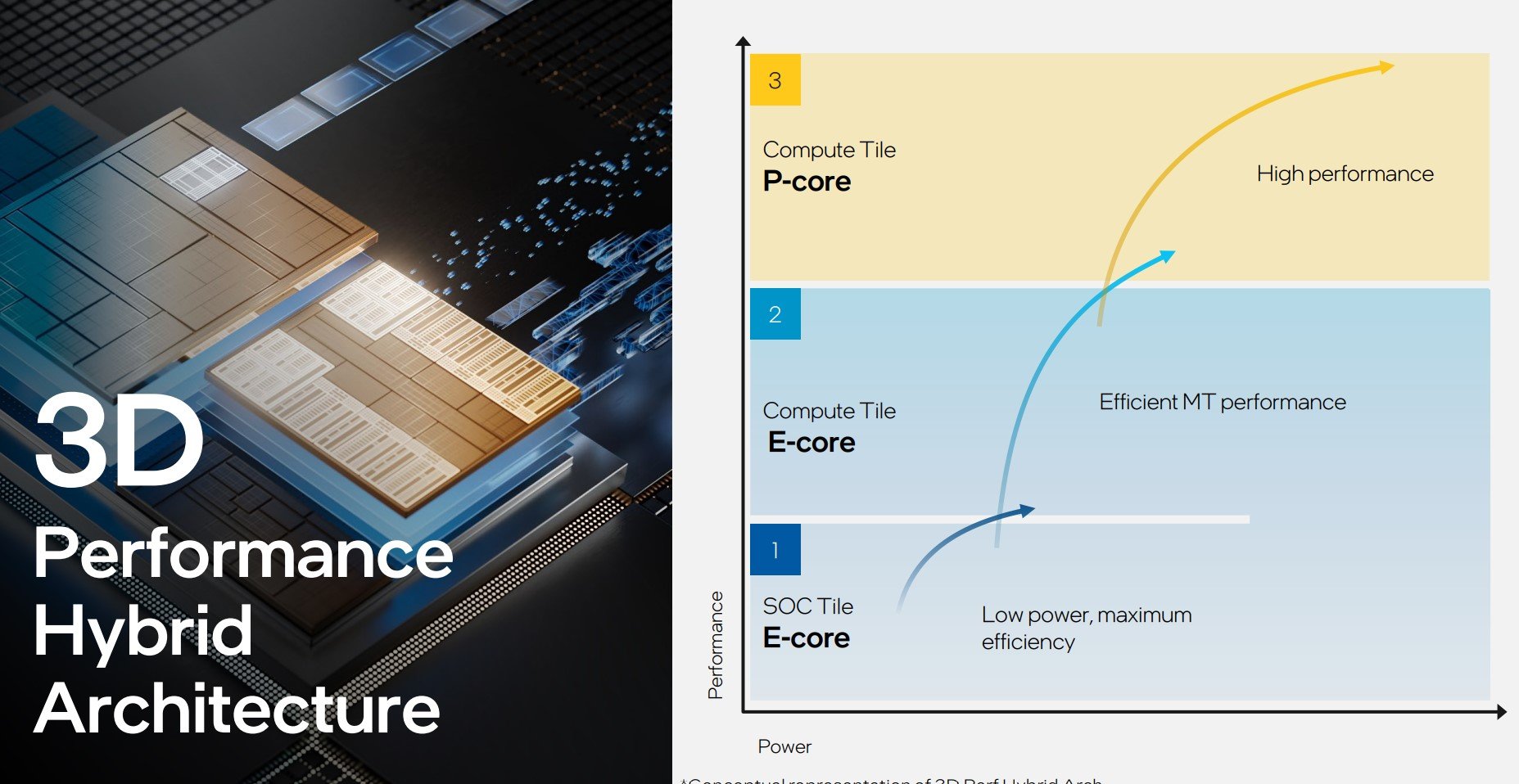
Appreciating the emergence of AI, this tile also carries an all-new NPU AI Engine. Purpose-built for low-power sustained AI workloads, Intel expects upcoming AI offload work to be done here, though depending upon application, AI can also be run on the CPU and GPU portions of the SOC. Sounds awfully similar to Apple’s ‘Neural Engine,’ if you ask me. Keeping up with the times, the tile further includes support for Wi-Fi 7, improved media capabilities, and is the physical home to the memory controller.
Shifting gears again, the TSMC-made Graphics Tile takes learnings of discrete Arc GPUs and pulls them into Meteor Lake, meaning the same architecture is present in both discrete and integrated solutions for the first time. Pushing out some numbers, Intel reckons Xe LPG graphics offer twice the performance and twice the performance per watt compared to current IGP baked into 12th and 13th Generation Core (Alder Lake and Raptor Lake). This still makes it difficult to ascertain quite how powerful they are in top-bin specification, but the hope is there’s enough horsepower to play popular esports games at common resolutions.

It remains to be seen if there’s enough grunt to displace AMD as the go-to IGP of choice in modern laptops, though there’s hope of improving framerate and visual quality through Arc technologies such as XeSS and ray tracing. Performance may not be as robust as on an equivalent discrete Arc (reduced-frequency A370M, by all accounts) due to a lack of XMX extensions on Meteor Lake.
Last but not least, the fourth and final segment is known as the IO Tile, and it supports both Thunderbolt 4 and PCIe Gen 5. Lassoing them together is that Foveros 3D technology, described as the “secret sauce” that makes disaggregation possible. There’s little point in having multiple tiles if moving data between them is prohibitively expensive from a power point of view.

Foveros 3D offers a super-tight bump pitch of just 36 micrometres and demands less than 0.3 pJ/bit of power. Putting this into context, back-of-the-envelope calculations suggest wire density and bump pitch is 10x tighter than on regular Intel packaging technologies, along with 10x higher energy efficiency. Quite simply, no Foveros 3D, no disaggregated Meteor Lake.
The quartet of tiles are strategically mounted on a base layer that helps connect them all together by channelling appropriate power and data.
Why Go Disaggregated?
The question quickly arises as to why Intel chose to go disaggregated for this generation when a regular monolithic die has worked well in the past. There are many reasons for this, all of which make sense, so let’s go through them. Building out different-function tiles ought to enable yields to remain high as failures in any one block don’t inhibit the entire chip from seeing the light of day.
This mix-and-match approach allows Intel to screen for blocks differently, use optimised manufacturing processes – you don’t need cutting-edge, expensive silicon for basic IO or display – and generally have far more flexibility than for a pure monolithic die. AMD, it must be said, came to the same conclusion with the chiplet-based Ryzen architecture many moons ago.
As Tim Wilson puts it succinctly, “The vast array of diverse IP in our SOCs today is starting to put strain on our ability to co-optimise all of them together, on a single process, in a monolithic SOC.” In other words, disaggregation of some kind had to come sooner or later: it become inevitable for cost and yield reasons.
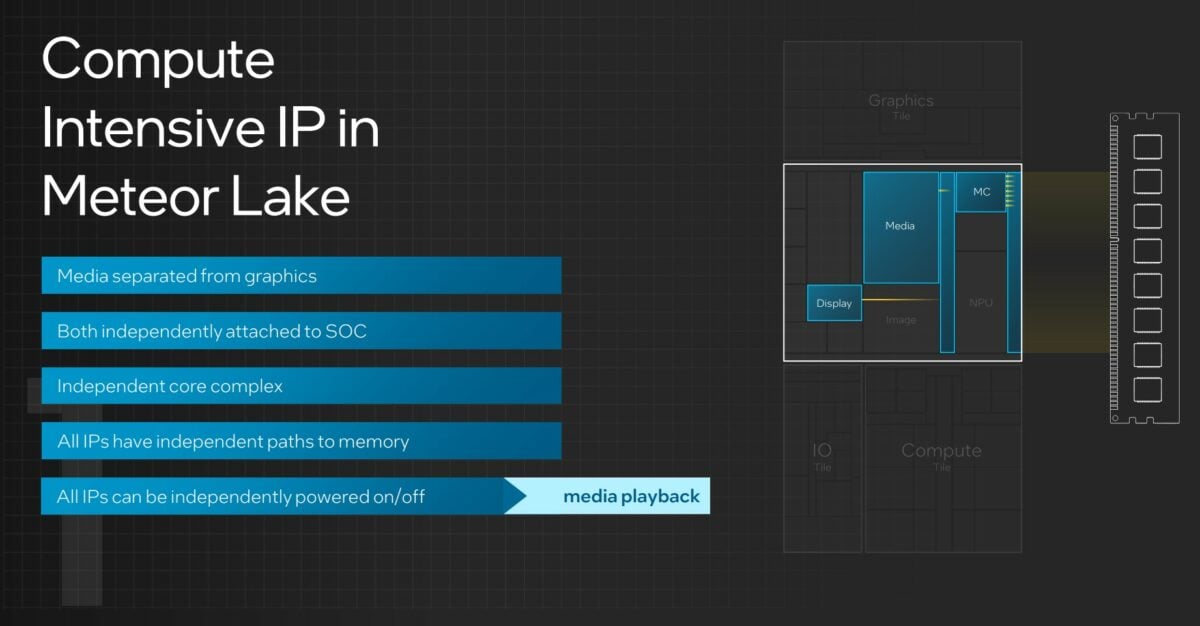
There’s also an advantage of architectural cleanliness. By separating out the tiles such that major IP blocks attach to the SOC fabric independently, enabling them to communicate with each other or system memory without having to go through other IP, there’s a certain elegance that was lacking before. Teasing this out further, one would expect per-IP block latencies to go down as there’s no need to traverse today’s array of multiple Intel ring stops.
Another positive effect of disaggregation is the ability to toggle the power states of each IP block without affecting others. For example, in scenarios where video playback is required, Meteor Lake can switch off the Graphics and Compute Tile, saving power and raising system efficiency by using only the IO Tile’s E-cores for minor processing. “The addition of the low-power island E-cores in the SOC allow us to provide computing capabilities to those workloads that value the lowest possible power at sufficient computing,” said Wilson.
Noting that IP blocks are consuming bandwidth at an ever-increasing rate, Meteor Lake’s SOC fabric is scalable enough to saturate the 128GB/s afforded by system memory and then dole out bandwidth to the IP blocks as and when requested. Sounding similar in principle to AMD’s Infinity Fabric, the main aim is to eliminate chip-wide bottlenecks.
Though no hard-and-fast specifications have been put forward, we expect to see best-of-breed Meteor Lake embody 14-core, 20-thread CPU functionality allied to 1,024-core GPU, all packaged up in a 45W configuration.
Summary
Meteor Lake is shaping up to be the most power-efficient Intel architecture ever. Offering up to 40 per cent savings compared to previous generations – a real boon for laptops – it also heralds a dedicated AI engine, three-tier Core hierarchy, and best-ever integrated graphics straight off the discrete Arc block.
Quite how all this complexity actually plays out is as yet unknown, but it’s clear the disaggregated approach provides Intel with a new-found level of modularity that’s necessary to leverage the best efficiency and performance in power-constrained environments. Arguably of less importance for desktop, we see Meteor Lake as the pre-eminent fit for 15-30W laptops that require a wide range of disparate functionality and even better battery life than present today through a one-size-fits-all monolithic strategy.
The future is all about tiles, and it’s coming soon to a laptop near you.